今年有不少国产大语言模型问世,根据各大评测榜单,部分模型的性能已经超越 GPT3.5,接近 GPT4 了。除了官方开发的大模型应用可供用户直接使用,各模型厂家也都提供大模型API服务供用户进一步 DIY。
官方应用为了吸引用户一般都是免费的,API 却价格不菲。那么,哪个大模型 API 最具性价比呢?
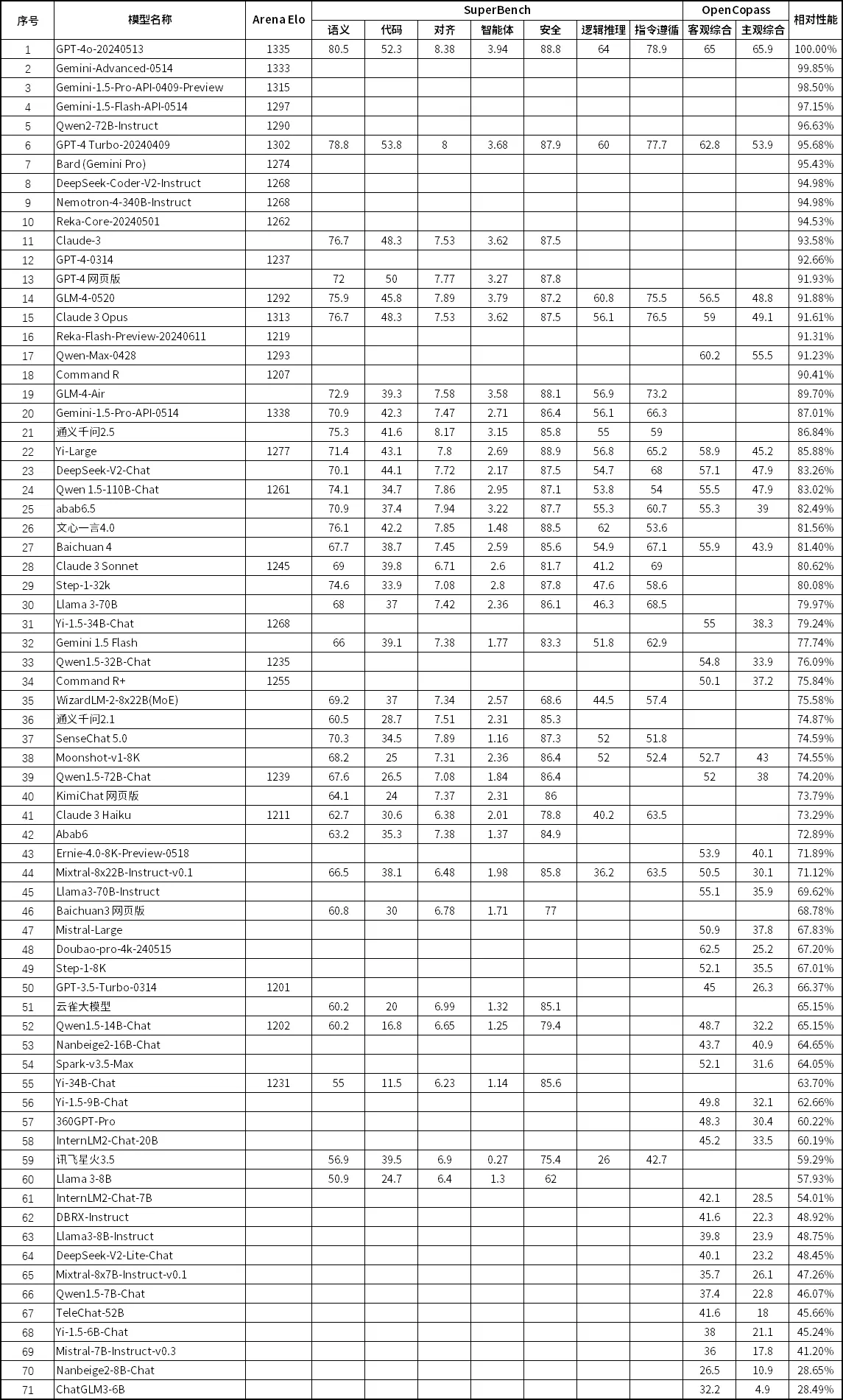
首先要量化大模型的性能。大模型的性能得分采用 LMSYS Chatbot Arena(chinese)、SuperBench、OpenCompass 三个大模型评测榜单的数据。以 GPT-4o-20240513 的得分为基准,用每个大模型的得分除以基准,得到相对于 GPT-4o 的性能得分。评测榜单中的每个单项分别计算相对性能得分,再取模型所有相对性能得分的平均数,用于性价比计算。这个相对性能意味着,在中文领域,某个大模型的性能可以达到 GPT-4o 的多少。
其次,大模型 API 的价格来自各厂家官方。国外大模型的价格可能随汇率有变动,但不影响最后的性价比排序,因为国外的大模型真的很贵。
最后,性价比计算采用(相对性能得分)除以(输入价格×0.2+输出价格×0.8)。与大模型对话中,一般输出 token 数量要远多余输入,所以取了个二八比例。
榜单得分和价格的搜集时间都是 2024 年 6 月 23 日。
各个大模型的性价比排序见下表 1。有些模型数据不全,因此只有价格或性能。大模型在评测榜单中的得分见表 2。
可以看到,论性价比,智谱的 GLM-4-AIR 遥遥领先,位列第一,具备 GPT-4o 89.7% 的性能,价格才 1 元/百万tokens,很适合不需要太强推理及代码的工作。深度求索的两个 DeepSeek 模型紧随其后,新出的 DeepSeek-Coder-V2 相对性能 94.98%,LMSYS Chatbot Arena 榜单上很能打,但输出价格高所以只能排第二。
表1↓
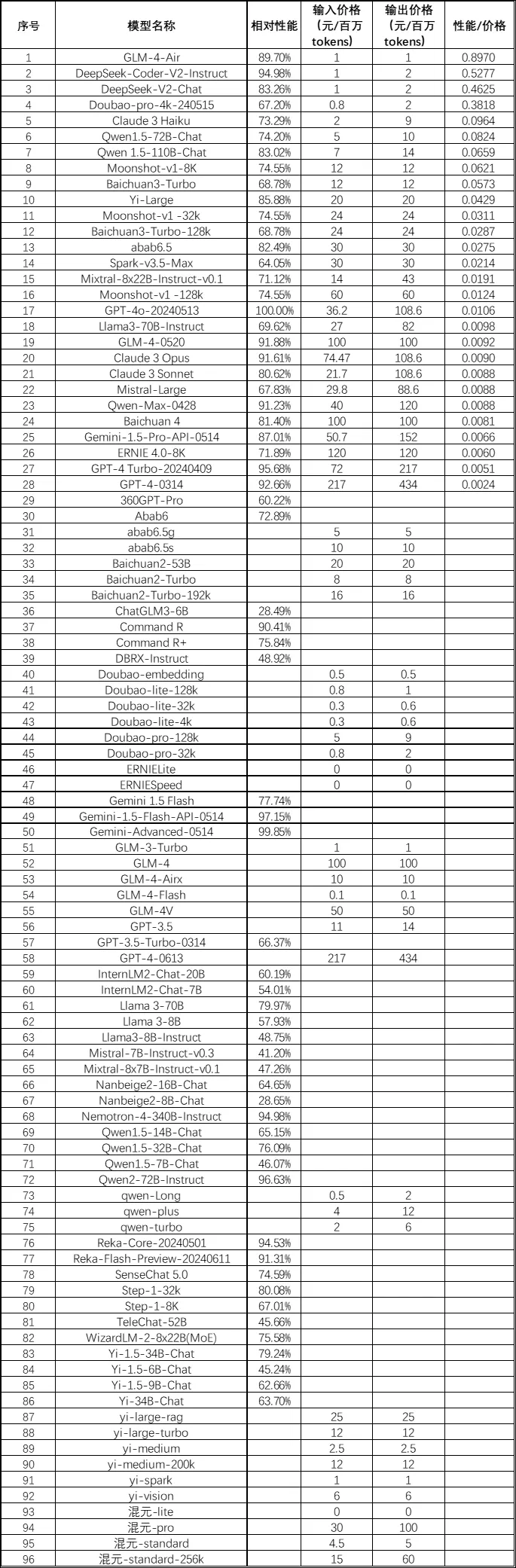
表2↓
本文作者:tsingk
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
预览: