数据文件为 Libreoffice 编制的 ods 类型,为了能直接读取 ods 文件生成 dataframe 格式数据,安装 pandas_ods_reader 包。
pip install pandas_ods_reader
然后导入相关库,读取数据。
pythonimport seaborn as sns
import pandas as pd
from pandas_ods_reader import read_ods
%matplotlib inline
ffftime = read_ods('dataset.ods', 1)
python# 挑取目标列数据
thedata = ffftime.loc[ffftime['人种']=='黄', ['连续输出1']]
print(len(thedata))
195
目标列中一共有 195 个待分析数据。对这些数据绘制直方图,查看各数据段内的分布占比,图中柱宽为 2。
python# 绘制密度分布图
rc = {'axes.unicode_minus': False}
sns.set(context='notebook', style='ticks', font='simhei', rc=rc)
ax = sns.histplot(data=thedata, x='连续输出1', binwidth=2, stat='proportion')
x = range(0, 50, 5)
ax.set_xticks(x)
ax.set_ylabel("占比", fontsize=14)
ax.set_xlabel("连续输出时间/min", fontsize=14)
ax.set_title('连续输出时间样本统计', fontsize=14)
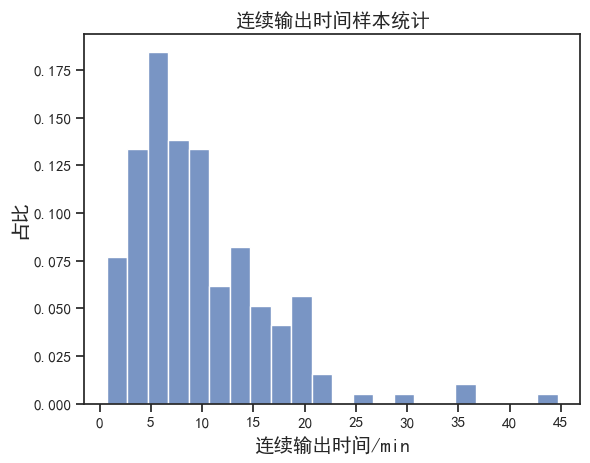
从占比直方图可以看出,5~7min 为占比最多区间,大约的18.5%样本落在此区间。
再绘制累计占比图。
pythonax1 = sns.ecdfplot(data=thedata, x='连续输出1', stat='proportion')
x = range(0, 50, 5)
ax1.set_xticks(x)
ax1.set_ylabel("累计占比", fontsize=14)
ax1.set_xlabel("连续输出时间/min", fontsize=14)
ax1.set_title('连续输出时间累计占比统计', fontsize=14)
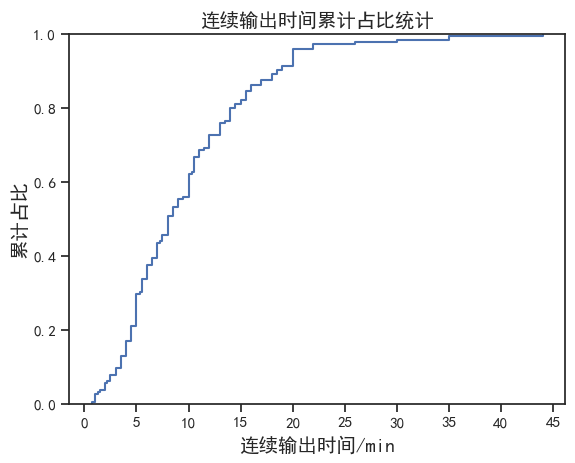
从累计占比看,大约 60% 的样本落在 10min 以下,意味着超过 10min 就算及格了。
本文作者:tsingk
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!