目录
起因
大概是年初,发现一款 Python 驱动的静态博客生成工具 Nikola。因为一直想学 Python,而且 Nikola 能够直接支持 Jupyter 格式的博文,不像其他博客系统需要额外插件和配置,所以就开始用 Nikola 写博客,同时可以倒逼自己学习 Python。恩,虽然那时 Python 也没咋学,更别提做数据分析,逼格反正先装到位了。
之前几年一直用 Farbox 博客,而后用 Typecho 做了几个月博客。改用 Nikola 后,虽然依然支持 Markdown 写的文章,但要求的文章的 front-matter 格式不同于 Farbox,也无法显示直接在 Typecho 中插入的图片。因此需要把用 Nikola 之前的所有博客文章做适当修改,转换为 Nikola 要求的格式。
博客文章数量虽然只有百来十篇,手动修改每一篇也太过无趣。反正在学 Python,不如把时间花来写个脚本自动修改转换这些博客文章。
需求分析
该 Python 脚本主要满足以下四个需求。
1. 修改 front-matter
Farbox 支持的 front-matter 格式如下,支持的属性不只这三条。但原博文都只使用了这三条:
title: 随便写个 date: 8102-02-29 tags: - farbox - 胡扯
需要把以上格式转换为下面这种 Nikola 支持的格式:
--- title: 用 python 转换博客文章,从 Farbox 到 Nikola slug: bo-ke-wen-zhang-zhuan-huan-cong-farbox-dao-nikola date: 2018-10-21 18:13:56 UTC+08:00 tags: - 博客,farbox - nikola - python category: python 菜鸟折腾记 ---
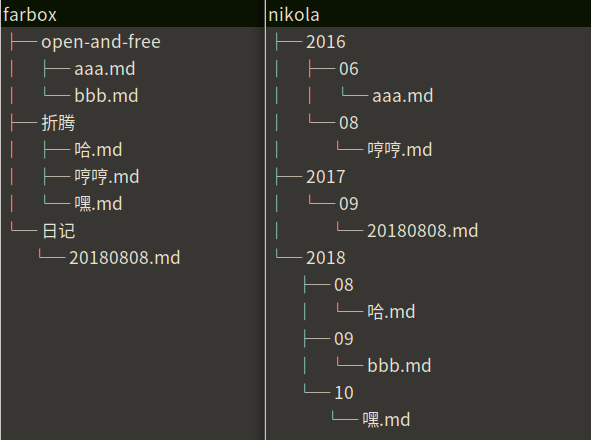
2. 博客文章目录结构修改
用 Farbox 时按照不同主题建立目录存放博客文章,用 Nikola 后则按照时间建立文章目录。于是需要将文章目录结构重新整理,按照发表时间把文章放进对应的目录中。
3. 修复失效的七牛云图片外链
最近因为七牛云的测试域名到期不能用了,导致之前用七牛云做图床的图片无法现实。需要将文章图片全部转移到腾讯云,然后修改相应的图片外链地址。
4. 批量修改博客文章
按照以上三条,可以批量修改指定根目录下及其子目录下的所有博客文章,输出到指定的修改后文件存储根目录,保留原文件。
功能实现
1. 目标任务
综合以上需求,该 Python 脚本需要完成的任务如下:
- 读取指定根目录下及其子目录下的所有文章文件名和路径;
- 对每篇文章完成如下修改:
- 自动识别字符编码;
- front-matter 自 farbox 格式转换成 nikola 格式;
- front-matter 中添加 slug,slug 由文章文件名转换成拼音生成;
- front-matter 中添加 category,category 由文章所在目录名称生成;
- 转换文章中七牛图片外链为腾讯云外链;
- 转换后的文章文本编码为 UTF-8;
- 插入 Nikola 支持的摘要符
- 在修改后文章存储根目录中,按文章发表日期建立「根目录-年-月」层级目录,存储转换后的博文。
2. 用到的关键模块和方法
2.1 利用 os.listdir() 获取文件名
利用 os 模块中的 listdir 函数,参数为指定目录路径,返回一个列表,包含该目录下所有子目录和文件的名称。
import os namelist = os.listdir("the-path-of-root")
由于原根目录为「根目录-主题」两级目录,则需要在获得根目录下所有「主题」目录名称后,对其做循环进一步读取各个「主题」目录下的文章文件名。
2.2 利用 os.path.join() 获取路径
获得文章名称后,利用以下 os 模块的函数获得文章的绝对路径。这个方法的好处是直接生成对应操作系统的路径格式,无须在意 Windows 系统路径中标新立异的反斜杠,从而使脚本能够在不同操作系统上运行。
afilename = os.path.join("所在目录绝对路径", "文件名")
2.3 利用 pinyin.get() 将文件名转换为拼音
使用 pinyin 模块的 get 函数,由文件名生成文章的 slug。参数为字符串,返回值为将参数中中文转换为拼音的字符串,可指定拼音之间的连接符。
import pinyin a = pinyin.get(filename.split(".")[0]) #参数为去掉扩展名的文件名
2.4 利用 chardet.detect() 获取文章字符编码
原博客文章中,除了 Markdowm 格式文件,还有不少 txt 格式的。因为编写时可能在 Windows 系统,所以部分 txt 文件字符编码是 ASCII 编码。用 Python3 打开文件时,需要指定字符编码,否则无法读取为字符串。所以为了实现批量处理,就必须自动识别字符编码。
利用 chardet 模块的 detect 函数,参数为文件的读取内容,返回值为一字典,字典中「'encoding'」键对应的值便是文件的字符编码。
import chardet afile = open(afilename, "rb") #打开为二进制 acontent = afile.read() codeType = chardet.detect(acontent)['encoding'] #解析出编码值
2.5 利用 file.readlines() 读取原文章
由于原文章中,front-matter 的格式为一行一个属性,所以打算按行为单位处理文章内容。利用文件的 readlines 方法,可以读取文章的每一行,生成列表返回,方便对文章每一行内容的操作。
3 代码实现
废话不多说,上代码。
pythonimport os
import pinyin
import chardet
def convertto(rootdir, filename, todir):
afilename = os.path.join(rootdir, filename) # 获取文件的绝对路径
if os.path.isfile(afilename): # 判断是否是文件而非目录
afile = open(afilename, "rb")
acontent = afile.read()
codeType = chardet.detect(acontent)['encoding'] # 获取文章的字符编码
afile.close()
afile = open(afilename, encoding=codeType)
acontent = afile.readlines() # 按行读取文章内容
acontent.insert(9, "<!-- more -->\n") # 在第 9 行插入摘要符
for line in acontent[0:3]:
if "date" in line:
blogdate = line.split(" ")[1].split("-") # 获取文章发表时间
datedir = os.path.join(todir, blogdate[0], blogdate[1]) # 生成存储目录的绝对路径
break
if not os.path.exists(datedir): # 如果目标存储目录不存在,则生成
os.makedirs(datedir)
bfilename = os.path.join(datedir, filename)
bfile = open(bfilename, "w", encoding='UTF-8') # 在目标目录中生成同名新文件
slug = "slug: " + pinyin.get(filename.split(".")[0], # 中文转拼音生成 slug
format="strip", delimiter="-") + "\n"
category = "category: " + os.path.split(rootdir)[1] + "\n"
bfile.write("---\n" + "" + acontent[0] + "" + acontent[1] +
"" + acontent[2] + slug + category + "---\n")
for line in acontent[3:]:
if line.find("bode.qiniudn.com") >= 0:
line = line.replace("http://xxx.qiniudn.com",
"https://xxx.file.myqcloud.\
com")
if line.find("/blog"):
line = line.replace("/blog", "")
bfile.write(line)
afile.close()
bfile.close()
def main():
bigdir = input("输入 farbox 博文所在目录:")
todir = input("输入转换后博文目录:")
for dirs in os.listdir(bigdir):
dirname = os.path.join(bigdir, dirs) # 获取根目录下子目录名
if os.path.isdir(dirname):
for filename in os.listdir(dirname): # 循环对子目录下每个文件进行处理
convertto(dirname, filename, todir)
if __name__ == "__main__":
main()
print("文本已转换至 nikola 子目录下")
测试运行效果
其实以上代码是边运行测试,边修改后的第 N 个版本。将转换后的文章生成 Nikola 博客检查效果,差强人意。仅两个小问题,一个是固定在每篇文章第 9 行插入摘要符,导致部分文章摘要太多或太少。另一个问题来自于,有两篇文章的名字区别仅在最后的数字,用 pinyin 模块转换出的拼音字符串是一样的,导致两篇文章的 slug 相同,进而 Nikola 报错。
这两个问题手动修改很容易,所以作为 Python 小白的这次折腾,虽然代码质量估计不咋地,但实现结果还算满意。
本文作者:tsingk
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!